In a similar fashion, if there are lots of distinct early reflections, then we instinctively deduce that the large room is mostly empty. If there are fewer early reflections, then we sense that the room contains objects that diffuse those reflections and cause them to smear together.
The reverberated component gives us further clues about the size of the room, and what its surfaces are made of. When the reverb decay time is long and the reflected sound closely resembles the original sound, we know two things — we’re in a large room, and the walls, floor, and ceiling are probably hard surfaces. Think about the sound of a bouncing basketball in a gymnasium, how bright the echoes of the bounce are, and how long they take to die out. But if we bounce the same ball on the same hardwood floor in a big theater with seats and drapes, the decaying sound will lose much of its high frequency content as the fabric and furniture in the room soak up the treble portion. The reverb “tail” may last as long, but it will sound duller than the original bounce sound.
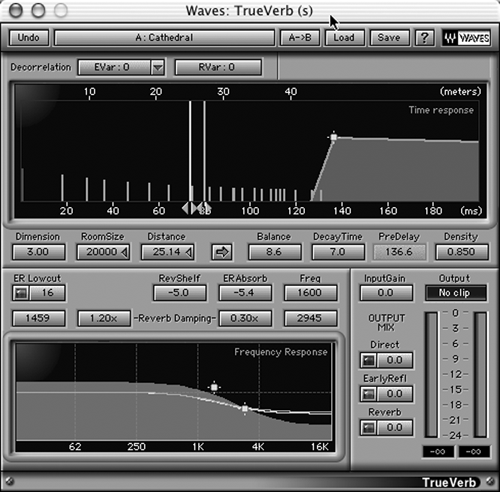
Finally, the ratio of direct sound to pre-delay and reverb tells us how far the original source sound is from us. The louder the direct sound portion is, the closer the sound source is to our ears. Look at Figures 2 and 3, both of which display the parameters available on a conventional digital reverb plug-in. Figure 2 shows a Cathedral program, while Figure 3 is a program to simulate a small recording room. Notice the spacing of the early reflections, the time and intensity of the reverb portion, and the EQ curves. All of these contribute to creating the audio illusion of space.
For the past twenty-odd years, this illusion has been accomplished with digital signal processing (DSP) algorithms that roughly mimic the results of the acoustical reverberation process. But despite a wide variety of adjustable parameters, these algorithms are often simply a series of sophisticated delays combined with digital equalizers and filters. The algorithms are well-understood and quite good, but often not realistic.
CONVOLVE THIS
Convolution offers another approach to simulating physical space, in which a signal is mathematically analyzed, and its characteristics are applied to another signal. Convolution algorithms have been used in digital audio for quite awhile, and several audio editors have a convolution function either built-in or available as a plug-in. The convolution is usually used in the frequency domain, and it’s prized by sound designers for its ability to mangle sound. You copy a bit of frequency-rich sound (an impulse) to the clipboard, and then apply the convolution function to your target audio. The software then multiplies the frequency spectrum of the clipboard sound and the target sound together, reinforcing the frequencies that the two have in common. It’s difficult to describe the results, but they can range from a subtle morphing of the two to all-out sonic mayhem.
But convolution isn’t just for sound designers anymore. It’s now being used to create reverb that more accurately mimics a particular physical space, by applying an impulse response to a digital audio file using convolution.
An impulse response is the response of a system, like a room, to an impulse, such as a short sine-wave sweep, a shot from a starter pistol, or some other audio spike. When you create an impulse in a room, you can easily hear the room’s response in the form of acoustical reverberation. By recording the impulse along with the resulting room response, then removing the original impulse, you’re left with just the response.
In other words, if you record a starter’s pistol in a room, then add the same pistol sound, 180 degrees out-of-phase, to the recording you just made, the pistol sound cancels out and you’re left with just the reverb created by the room.
Once you’ve isolated the room’s impulse response, you can apply it to each sample of any digital audio file. Each sample acts like an impulse, and the cumulative effect of convolving the impulse response with all those impulses in quick succession re-creates the sound of that signal in that room.
In other words, you produce an audio spike in a meat locker, then run the recording through a number cruncher to isolate the impulse response. You then apply that impulse response to your favorite big-voice VO guy to hear him doing his big-voice thing from inside a meat locker. (Hey, bet that would work with a recording of the GM... ummm... never mind.)
The convolution calculations are complicated and need a fast processor. In fact, until recently convolution was an entirely off-line and non-real-time process. But it produces a sound that is less artificial-sounding than the traditional digital reverb utilizing filter networks, and it generates reverberation that is both dense and very smooth, with none of the looping artifacts that are sometimes present with regular reverbs.
The CPU chips in computers are now fast enough to create impulse response reverbs in real time, although the good ones will eat your CPU and leave little power for other tasks. But most of them sound good enough to actually dedicate a computer to nothing but IR reverb. Given that a good Lexicon or TC reverb costs several thousand dollars, a dedicated computer starts to look the bargain by comparison.